Claude 近期服务质量下降问题复盘:三个“幽灵”Bug 的幕后故事
Posted September 17, 2025 by XAI 独立观察员 ‐ 6 min read
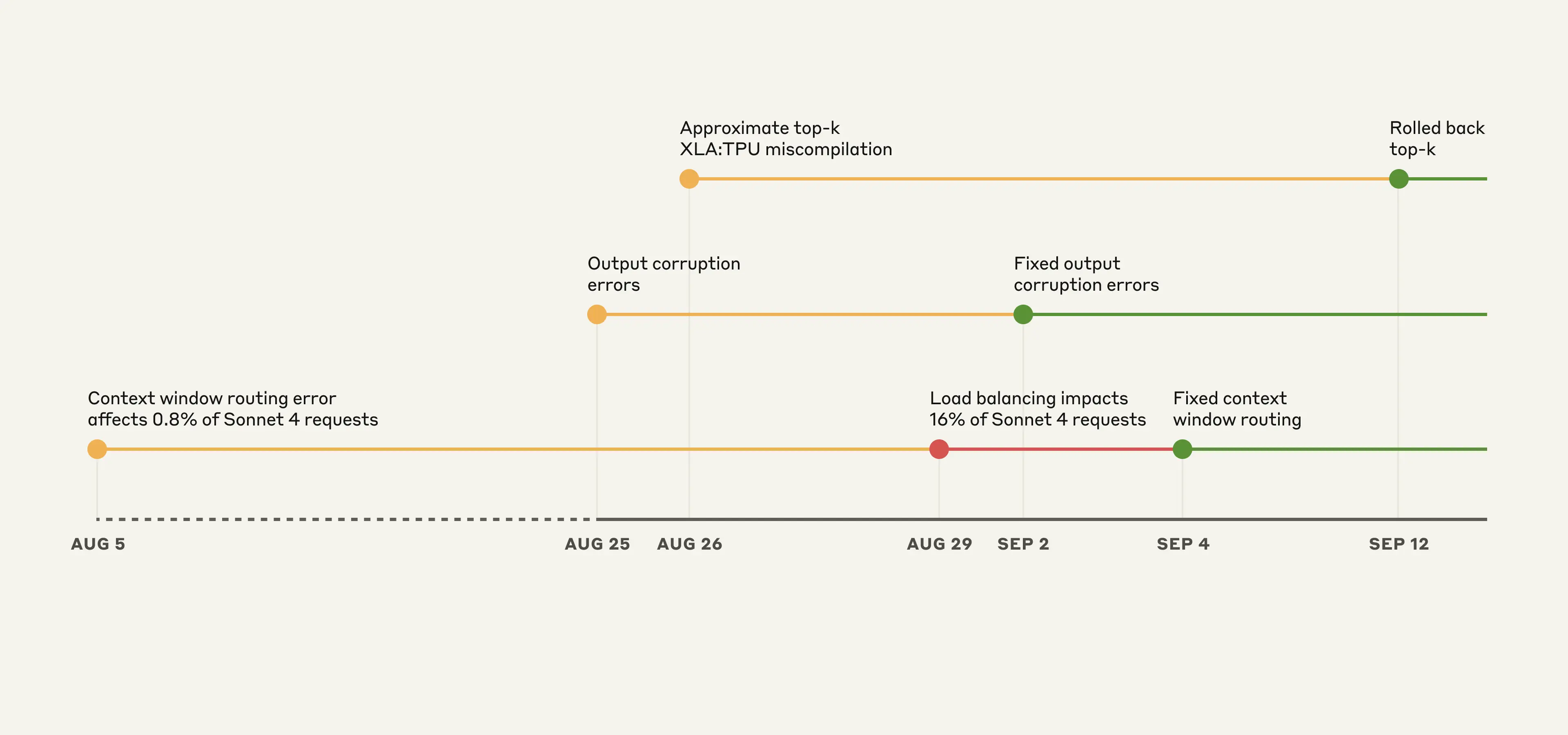
如果你在8月到9月初感觉 Claude 有时“变笨了”,那不是你的错觉。Anthropic 官方发布了一份详细的技术复盘(原文链接),承认了问题的存在,并坦诚地解释了背后复杂的原因。官方强调:绝不是因为服务器忙就故意降低模型质量,问题完全由基础设施 Bug 导致。
发生了什么?一句话总结
从8月初到9月中旬,三个独立的、相互重叠的基础设施 Bug,像“幽灵”一样间歇性地影响了 Claude 的部分模型(特别是 Sonnet 4),导致一些用户的体验下降。由于问题相互交织,给排查带来了巨大困难。
三个“肇事”的 Bug
官方详细披露了三个问题的技术细节,我们可以将其通俗地理解为:
1. “走错路”的请求 (上下文路由错误)
- 问题:部分处理“短对话”的请求,被错误地发送到了为“超长对话”(1M 上下文)准备的服务器上。这就好比让短跑选手去跑马拉松赛道,状态自然不对。
- 影响:最初只影响 0.8% 的请求,但8月底一次负载均衡调整,无意中放大了问题,高峰时影响了 16% 的 Sonnet 4 请求。更糟糕的是,路由具有“粘性”,导致部分用户会持续遇到问题。
- 波及范围:主要影响 Claude 官网、API 及 Google Cloud 用户,Bedrock 平台受影响极小。
2. “乱码”的输出 (输出内容损坏)
- 问题:一个性能优化配置的失误,导致模型在生成内容时,会偶尔蹦出一些不相干的字符。比如,你用英文提问,回复中间可能突然出现一个泰语“สวัสดี”。
- 影响:主要影响了8月25日至9月2日期间,在 Claude 官网上使用 Opus 和 Sonnet 模型的用户。
- 波及范围:第三方平台(如 Bedrock, Vertex AI)未受此问题影响。
3. “算错数”的编译器 (XLA:TPU 编译错误)
- 问题:这是一个潜伏已久的编译器底层 Bug。一个旨在提升选词效率的新代码,意外触发了这个 Bug,导致模型在选择下一个词时出现偏差,影响了生成内容的质量。
- 影响:这个问题非常“狡猾”,时好时坏,难以复现。主要影响了 Haiku 3.5 模型,并可能波及 Opus 3 和 Sonnet 4。
- 波及范围:同样,第三方平台未受影响。
为什么花了这么长时间才修复?
诊断过程之所以如此艰难,主要有三个原因:
- 问题叠加,症状混乱:三个 Bug 同时发生,产生的现象五花八门,让工程师很难定位到单一的根本原因,看起来就像是随机的、无规律的性能下降。
- 常规检测手段失效:现有的自动化评测基准,没能有效捕捉到这种细微但影响用户体验的质量下降。模型强大的纠错能力有时会掩盖掉小错误。
- 用户隐私保护的“幸福烦恼”:出于对用户隐私的严格保护,工程师无法直接查看导致问题的用户对话记录,这使得复现和调试问题变得异常困难。
未来会如何改进?
亡羊补牢,为时未晚。Anthropic 承诺将进行以下改进,以防止类似事件再次发生:
- 更灵敏的“照妖镜”:开发更敏感、更精细的评测系统,能像“显微镜”一样发现微小的模型质量变化。
- 深入“生产一线”的持续监控:将质量评测直接部署在真实的生产系统上,进行7x24小时不间断监控,以便第一时间发现类似路由错误的异常。
- 更快的“侦探”工具:开发新的内部工具,在保护用户隐私的前提下,帮助工程师更快地根据社区反馈来定位和调试问题。
本文是对官方报告的总结和解读,感兴趣的读者可以阅读官方技术报告原文以了解更深入的技术细节。